Følgende dokument giver et teknisk overblik over struktur og opbygning af SkoleGPT.
SkoleGPT består af to seperate komponenter:
- En webserver der håndterer UI, og står for kald til den bagvedliggende sprogmodel.
- En webserver der indeholder sprogmodellen. Den modtager kald og genererer svar
I skrivende stund er sprogmodellen Gemma3 12B, men den kan skiftes ud med en anden model hvis det ønskes.
Løsningen er hostet hos DBC Digital i deres datacentre i Danmark. Der kræves ingen login, og hverken spørgsmål eller svar bliver gemt. Denne tilgang er valgt for at prioritere brugernes sikkerhed og sikre fuld overholdelse af GDPR. Som det eneste logger vi antal kald og svartider for at kunne overvåge systemets tilstand.
Systemisk overblik
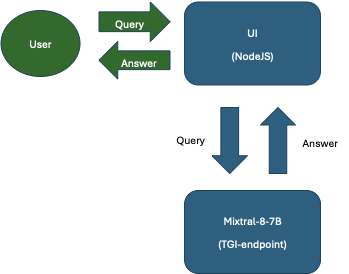
Både text-generation-inference endpointet og UI endpointet er deployet i flere instancer for at maksimere throughput og gøre det stabilt i fohold til eventuelle udfald.
Webserver
Applikationen er skrevet i NodeJS+typescript og anvender frameworket NextJS. Applikationen er en videreudvikling af opensource projektet Chatbot UI og er valgt for at videreføre den første udgave af SkoleGPT projektet. Chatbot UI er udgivet under MIT Licens.
Udover prompt har brugeren også mulighed for at specificere 3 yderligere model parametre:
- Systemprompt: Dette er den grundlæggende instruktion, som modellen modtager, inden noget andet behandles. Den definerer modellens fundamentale adfærd, såsom hvilket sprog den skal besvare spørgsmål på.
- Temperatur: Bestemmer modellens grad af kreativitet (lav temperatur = mere præcis og fokuseret, høj temperatur = mere kreativ og varieret).
- Top-P: Angiver, hvor stor en del af det samlede sandsynlighedsfelt modellen vælger sine svar fra. For eksempel betyder en Top P på 0,9, at modellen ignorerer ord, som samlet udgør mindre end 10% af sandsynligheden.
Modellen
Både modellen og serveren er huggingface komponenter. Text-generation-inference endpointet er hentet ned gennem docker og deployet i vores egne datacentre med den ønskede model.
- Model: Gemma3 12B
- Inference-endpoint: text-generation-inference
I øjeblikket bliver hver af de to instancer af inference endpointet hostet på 2 dedikerede L40S GPU’er, dvs 4 GPU’er i alt.
Teknisk beskrivelse af guardrail-implementation for LLM
I SkoleGPT er der implementeret guardrails i form af et pre-filter, der opdager uønsket brugerinput, som potentielt kan få den bagvedliggende sprogmodel til at generere svar, vi ikke ønsker at SkoleGPT skal give. Filteret fungerer ved at kalde en sprogmodel med en prompt, der definerer de typer input, vi ønsker at afvise, og bede den om at vurderer om brugerinput er uønsket.
Ved at anvende en sprogmodel – i stedet for en simpel liste med stopord eller stopfraser, gør filteret mere robust over for variationer i sprogbrug, stavefejl og lignende.
Filteret er testet på 200 inputs, hvoraf 100 var uønskede. Det opnåede en nøjagtighed på 99 %, sammen med de indbyggede guardrails i selve sprogmodellen har vi dermed markant reduceret risikoen for uønsket output.